library(foreign) # Para convertir datos *.dta (STATA)
library(haven) # Para importar datos de otros programas
library(readxl) # Para leer archivos de excel
# Ejemplo de una base de datos que esta en excel (debe tener cuidado con la ruta de su computador C:)
Pruebadatos <- read_excel("Prueba.xlsx")
View(Pruebadatos) # Para explorar la base
#Exportar una base de datos desde R a formato CSV de excel con el comando "write"
write.csv(Pruebadatos, file = "archivodeprueba.csv")2: Datos

Hoy estarás mirando como se trabaja con datos en R, podras ver una forma en video, otra de forma manual siguiendo la lectura de esta página. La idea es que termines creando tu propio conjunto de datos.
Video
Resumen
Consecuente a lo que venimos haciendo en el curso de econometría I. Esta parte contiene lo referente a la importación de datos en distintos formatos y las primeras medidas en estadística básicas conocidas como medidas de tendencia central , estas se usan para el análisis de datos, al igual que el tema de la distribución de una variable.
Markdown
Un compilador potente que permite juntar códigos de R, ecuaciones de LaTeX y textos para obtener documentos científicos ya sea en formato de html, pdf y/o word. Se puede desplegar desde el menu de R Studio. Una guía completa de él lo puede hallar en este enlace y su creador es Yihui Xie.
Los archivos de Markdown tienen varios campos para completar o llenar. Los primeros son los títulos, estos deben ser usados con el operador (#), que indica principal, secundario, subtitulo y así.
| Formato | Salida |
|---|---|
| # | Titulo |
| ## | Subtitulo |
| ### | Subsubtitulo |
Como también para colocar algo en negrilla es con \((**)\) y en el estilo de cursivas con un solo asterisco \((*)\).
Por ejemplo, si hago uso de los asteriscos simples *carlos* dará como resultado carlos, o si usa los dos (doble) asteriscos como p.e: **carlos** tendremos en el la casilla en negrilla, p.e: carlos
Chunks
El siguiente elemento son los chunks estos son una especie de integrador del código del programa con elementos del formato en el cual este redactando o haciendo un informe de Markdown.

Es importante tener presente cada uno de los elementos que conforman el chunk, ademas de colocarle un nombre único comentarios y las opciones de estos.
Importar bases de datos
Las bases de datos que vienen en múltiples formatos distintos a los de R deben ser importados a partir de paquetes como foreign, haven, readxl, entre otros. Un ejemplo de esto es:
Otra forma de hacerlo es con la ayuda del menú de R Studio
Es de recordar que al exportar datos, estos quedan grabados en la carpeta de trabajo1 que se le ha establecido al programa desde un inicio.
Manejo de datos y variables
En algunas ocasiones, a los datos le harán falta variables nuevas, o habrá necesidad de crear o adicionar mas datos. Una manera de hacerlo es con el paquete de dplyr del conjunto de tidyverse2.
library(tidyverse)
tbl_df(Pruebadatos) # Para formato tibble# A tibble: 9 × 3
Consumo Ingreso Precios
<dbl> <dbl> <dbl>
1 15 795000 5400
2 18 893400 5200
3 25 956920 5100
4 29 987200 4800
5 30 998564 4700
6 45 999300 4500
7 16 840200 5300
8 31 998800 4700
9 10 532900 4600glimpse(Pruebadatos) # Mirar las variablesRows: 9
Columns: 3
$ Consumo <dbl> 15, 18, 25, 29, 30, 45, 16, 31, 10
$ Ingreso <dbl> 795000, 893400, 956920, 987200, 998564, 999300, 840200, 998800…
$ Precios <dbl> 5400, 5200, 5100, 4800, 4700, 4500, 5300, 4700, 4600# Para crear una nueva variable puede hacerlo con:
df=mutate(Pruebadatos, ahorro=Ingreso-(Consumo*Precios))
df# A tibble: 9 × 4
Consumo Ingreso Precios ahorro
<dbl> <dbl> <dbl> <dbl>
1 15 795000 5400 714000
2 18 893400 5200 799800
3 25 956920 5100 829420
4 29 987200 4800 848000
5 30 998564 4700 857564
6 45 999300 4500 796800
7 16 840200 5300 755400
8 31 998800 4700 853100
9 10 532900 4600 486900Si se logra notar, se tiene ahora una base de datos con una nueva variable3.
Añadir filas en el formato dplyr se puede hacer de la siguiente forma:
Pruebadatos %>% add_row(Consumo = 39, Ingreso = 895400, Precios=4700)# A tibble: 10 × 3
Consumo Ingreso Precios
<dbl> <dbl> <dbl>
1 15 795000 5400
2 18 893400 5200
3 25 956920 5100
4 29 987200 4800
5 30 998564 4700
6 45 999300 4500
7 16 840200 5300
8 31 998800 4700
9 10 532900 4600
10 39 895400 4700Recuerde que para las columnas (variables) se usa es la función del paquete dplyr y cu mutate.
Operador Pipe
El operador pipe %>% ayuda a simplificar las lineas de código de tal manera que condensa o adjunta múltiples ordenes en pocas lineas:
y<- mean(log(x)) # Es similar a
y<- x %>% log %>% meanEn sintesis organiza las ordenes del código, lo anterior dice que con el objeto de x calcule el logaritmo y luego el promedio. Otro ejemplo o secuencia es:
Mire la siguiente linea bastante compleja en R si se opta por no usar el operador. Asuma la siguiente orden: Encuentre las llaves, desbloquea, maneja el carro hasta la U y finalmente parquea.
parquea(conduce(prender_carro(encuentra("llaves")),a= "Universidad"))Cuando usa el operador %>% la orden es mucho mejor y puede escribirla como:
encuentra("llaves") %>%
prender_carro() %>%
conduce(a= "Universidad")
parquea()De esta manera es mas limpio y claro lo anterior. Para hacer uso del operador es recomendable haber instalado el paquete tidyverse.
Caracterización de los datos
La importancia del análisis de datos (EDA) es requerida para tomar decisiones y conocer muy bien lo que cada una de las variables nos esta indicando, es por esto que recurrimos a la estadística y hacemos uso de las distintas medidas de tendencia central ampliamente conocidas como media, desviación estándar, asimetría y curtosis.
\[ \begin{aligned} \text{Promedio } =& \frac{\sum_{i=1}^{n} x_{i}}{n} = \bar{x} \\ \text{Varianza } =& \frac{\sum_{i=1}^{n} (x_{i} - \bar{x})^{2}}{n} = Var(x) \\ \text{Asimetría}=& \frac{\sum_{i=1}^{n} (x_{i} - \bar{x})^{3}}{\sigma^{3}} = A(x) \\ \text{Curtosis }= & \frac{\sum_{i=1}^{n} (x_{i} - \bar{x})^{4}}{n\sigma^{2}}-3 = K(x) \end{aligned} \] Donde n es el tamaño de la muestra, x las observaciones, \(\sigma\) la desviación estándar, \(\bar{x}\) la media de la distribución. Con una base de datos podemos entonces tener:
# Promedio de una variable:
mean(Pruebadatos$Consumo)[1] 24.33333Que hace el respectivo cálculo de el promedio de la variable en cuestión, como lo es en este caso el Consumo. Para el cálculo de la mediana (segundo momento de una distribución) podemos hacerlo de la siguiente forma
# Mediana:
median(Pruebadatos$Consumo)[1] 25Con respecto a la varianza y la propia desviación estándar de la variable se hace uso de
# Desviación estándar:
sd(Pruebadatos$Consumo)[1] 10.77033# Varianza
var(Pruebadatos$Consumo)[1] 116Pero incluso podemos tener todo el bloque básico completo a partir de la función que resume todas y cada una de estas en el grupo de variables que tenemos dentro de nuestra base de datos
# Un resumen completo
summary(Pruebadatos$Consumo) Min. 1st Qu. Median Mean 3rd Qu. Max.
10.00 16.00 25.00 24.33 30.00 45.00 Que son los cálculos por variable de las primeras medidas de estadística descriptiva. La interpretación de cada uno de ellos es vital en el análisis de datos. Para el calculo del tercer y cuarto momento hay que hallar y tener en cuenta la instalación del paquete de moments
# Usar paquete Momentos de la distribución
library(moments)
# Asimetría
skewness(Pruebadatos$Consumo)[1] 0.5111471# Curtosis
kurtosis(Pruebadatos$Consumo)[1] 2.530456En este caso la asimetría nos dice que tan sesgada hacia un lado esta la distribución de los datos, la recomendación de asimetría es que esta sea cero (0), o se encuentre cerca de ese valor y la Kurtosis el grado de punta que tiene la distribución, se puede de acuerdo al valor obtenido clasificar como:
\[\begin{aligned} \text{Mesocurtica}: \; & K = 3 \\ \text{Leptocurtica}: \; & K > 3 \\ \text{Platicurtica}: \; & K < 3 \end{aligned}\]
Paquete dplyr
Con tidyverse también puede gestionar estadísticas, esto lo puede hacer con los comandos que se exponen a continuación:
summarise(Pruebadatos, Promedio=mean(Consumo))# A tibble: 1 × 1
Promedio
<dbl>
1 24.3Lo anterior nos brinda en un estilo de \(\bar{x}\) de forma única o solo para una variable. Si queremos mirar en grupo.
summarise_each(Pruebadatos, funs(mean))# A tibble: 1 × 3
Consumo Ingreso Precios
<dbl> <dbl> <dbl>
1 24.3 889143. 4922.Y con eso tendremos todas los promedios del caso. Hay otras opciones dentro de las funciones de dplyr para hallar valor mínimo o (min), el máximo, la varianza, entre otros.
Paquete skimr
Lo anterior también puede hacerlo con el paquete de skimr, que compila e incluso llega a gráficar. Para hacer uso de él debe establecer
library(skimr)
skim(Pruebadatos)| Name | Pruebadatos |
| Number of rows | 9 |
| Number of columns | 3 |
| _______________________ | |
| Column type frequency: | |
| numeric | 3 |
| ________________________ | |
| Group variables | None |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| Consumo | 0 | 1 | 24.33 | 10.77 | 10 | 16 | 25 | 30 | 45 | ▆▂▇▁▂ |
| Ingreso | 0 | 1 | 889142.67 | 153511.64 | 532900 | 840200 | 956920 | 998564 | 999300 | ▂▁▂▃▇ |
| Precios | 0 | 1 | 4922.22 | 330.82 | 4500 | 4700 | 4800 | 5200 | 5400 | ▅▇▁▅▅ |
Distribución de una variable
La distribución de una variable \(x\) siempre es necesaria. Con esto podemos identificar ciertos patrones comunes.
#Gráficos esenciales
curve(x^2, -2, 2)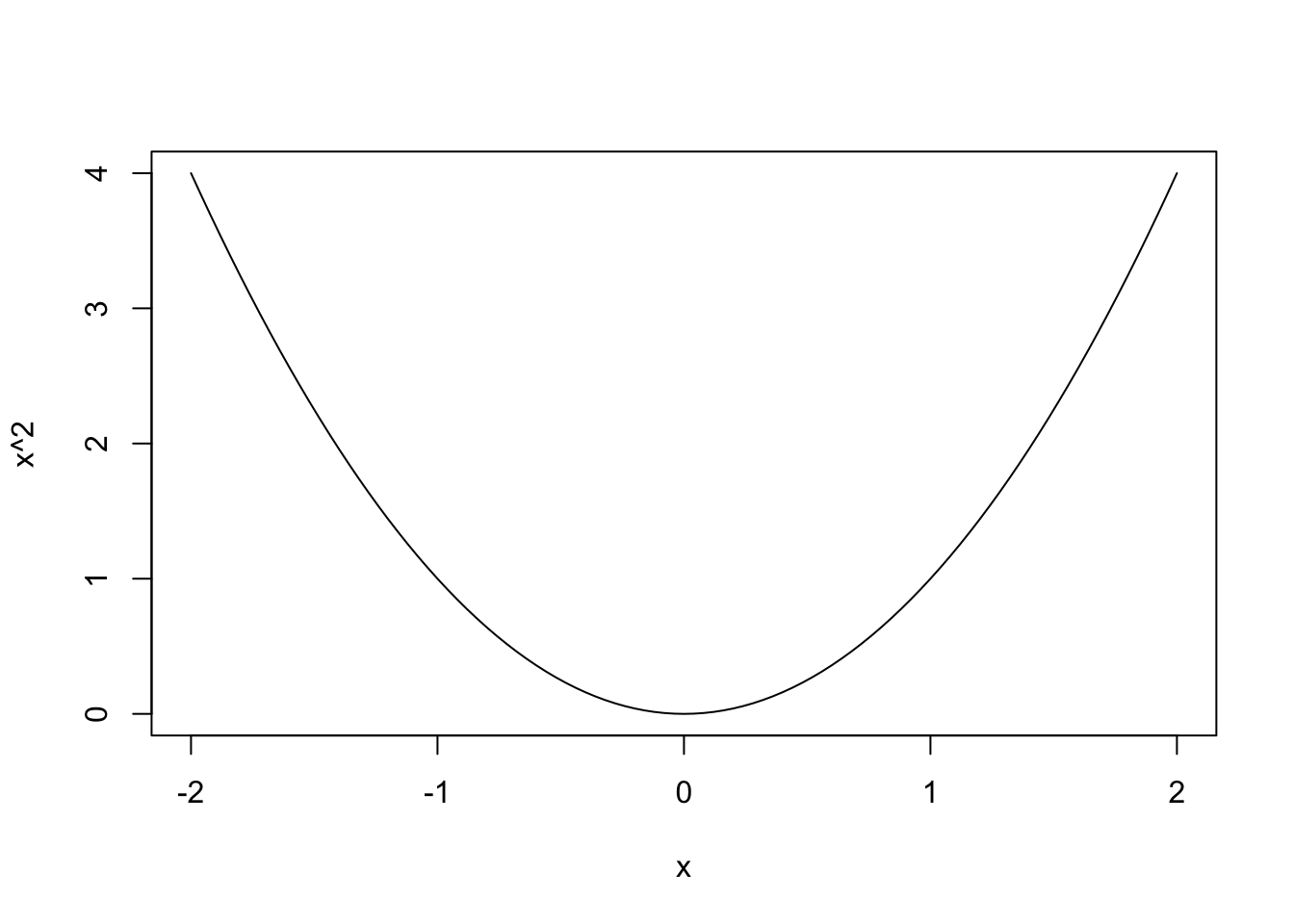
curve(dnorm(x), -3, 3)
#Algunas etiquetas y estilos
curve(dnorm(x,0,1), -10, 10, lwd=1, lty=1)
curve(dnorm(x,0,2), add=TRUE, lwd=2, lty=2)
curve(dnorm(x,0,3), add=TRUE, lwd=3, lty=3)
#De lo anterior pero con etiquetas
#Adición de etiquetas
legend("topleft", expression(sigma==1, sigma==2, sigma==3), lwd=1:3, lty = 1:3)
#Adición de formula centrada en x=6 y y=0.3
text(6, .3,
expression(f(x)==frac(1, sqrt(2*pi)*sigma)*e^{-frac(x^2, 2*sigma^2)}))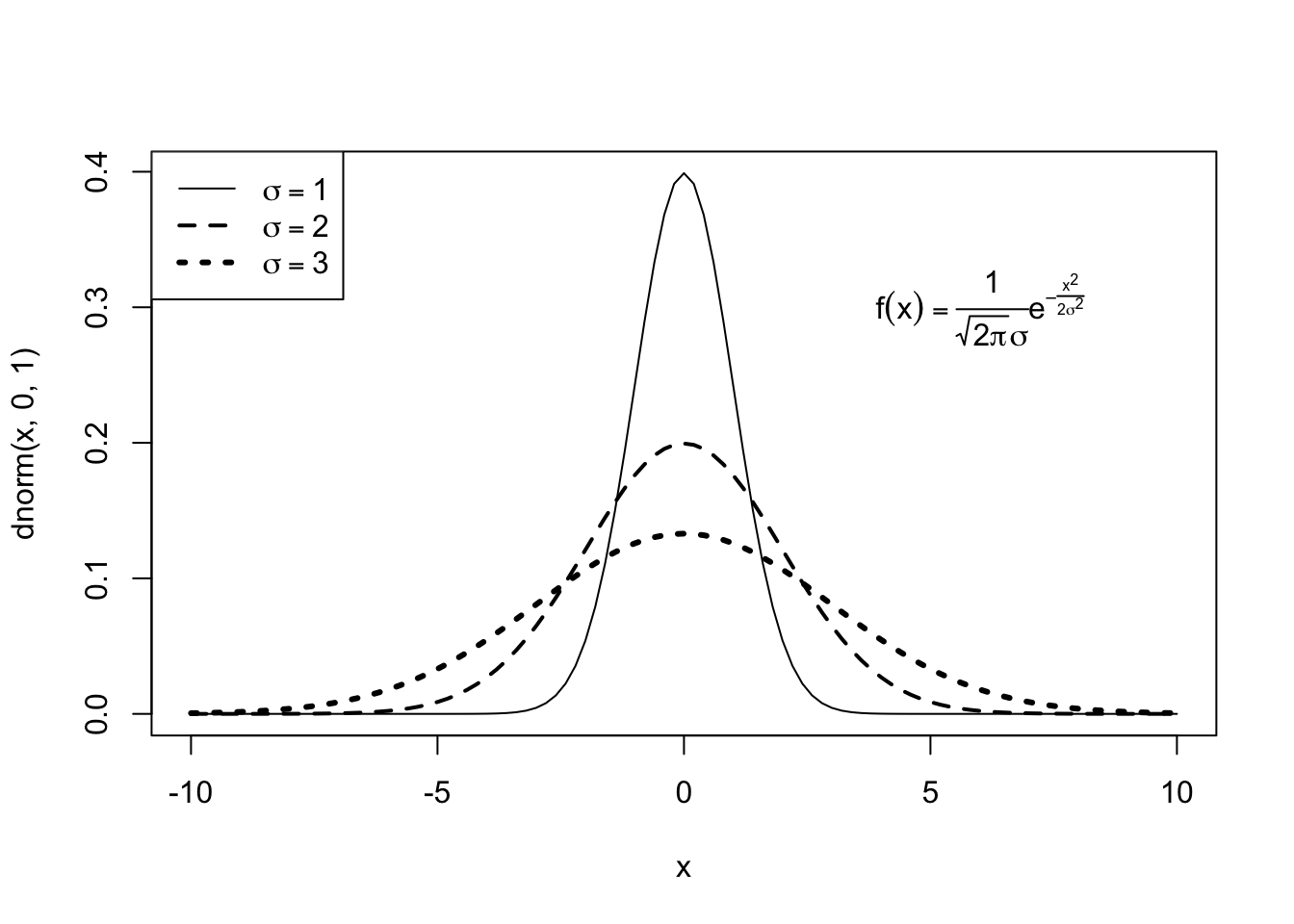
La opción de expression permite escribir ecuaciones y textos dentro del gráfico. Siempre es bueno tener en consideración la posición que queremos que tenga.
Histogramas
El histograma es uno de los primeros gráficos de uso para conocer mejor el punto de la distribución de variables. Con esto nos indica que proporción de observaciones contiene una característica en particular. Los histogramas pueden señalar que tan asimétricos son las observaciones y si existe o no un sesgo en la cola de la distribución.
# Extraer datos para un vector
PRS <- Pruebadatos$Consumo
# Figura (a): histograma (para orden y conteo)
hist(PRS)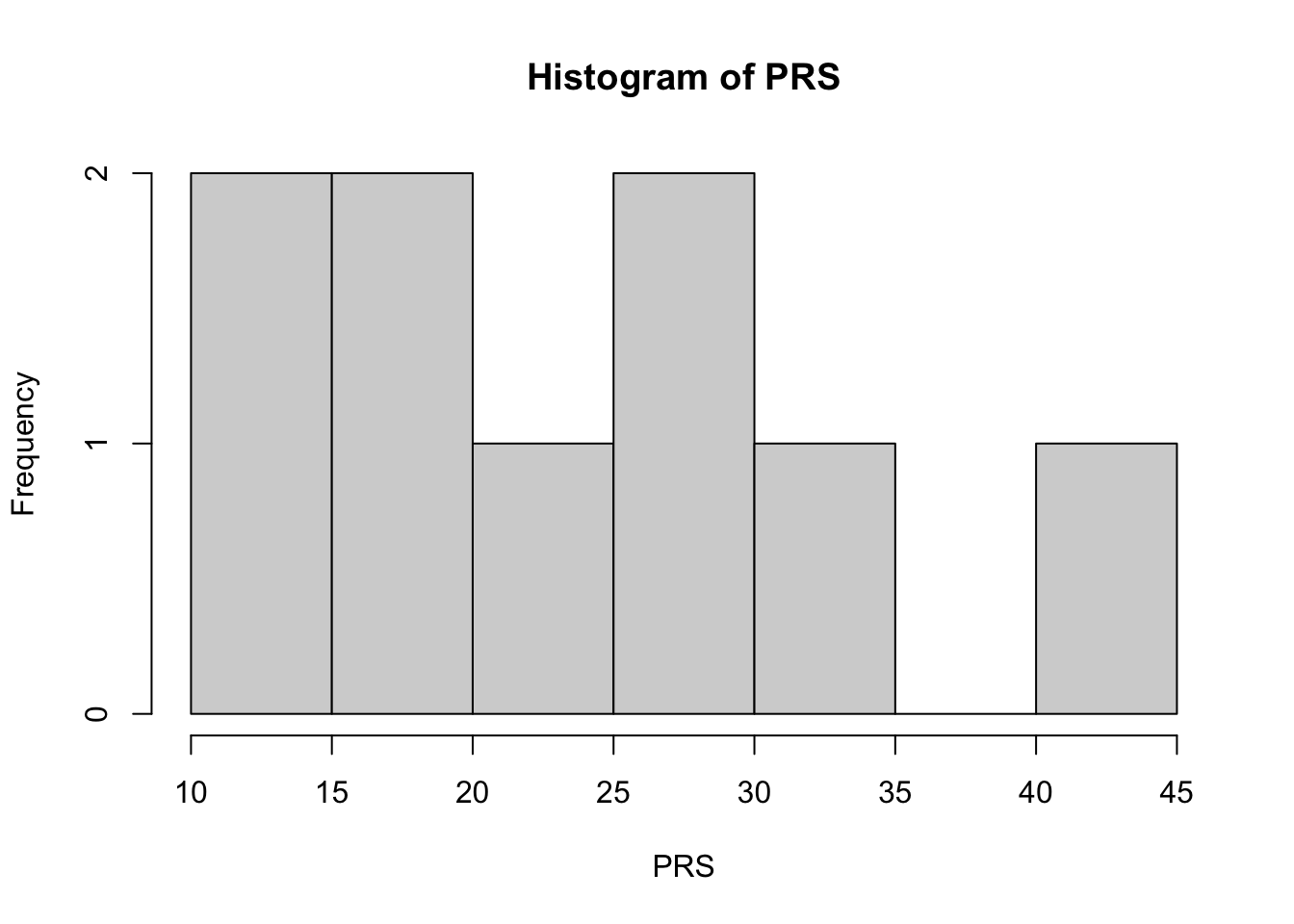
# Densidad de la variable y aplicación con colores
d <- density(PRS)
plot(d, main="Densidad Kernel del Consumo")
polygon(d, col="blue", border="red") 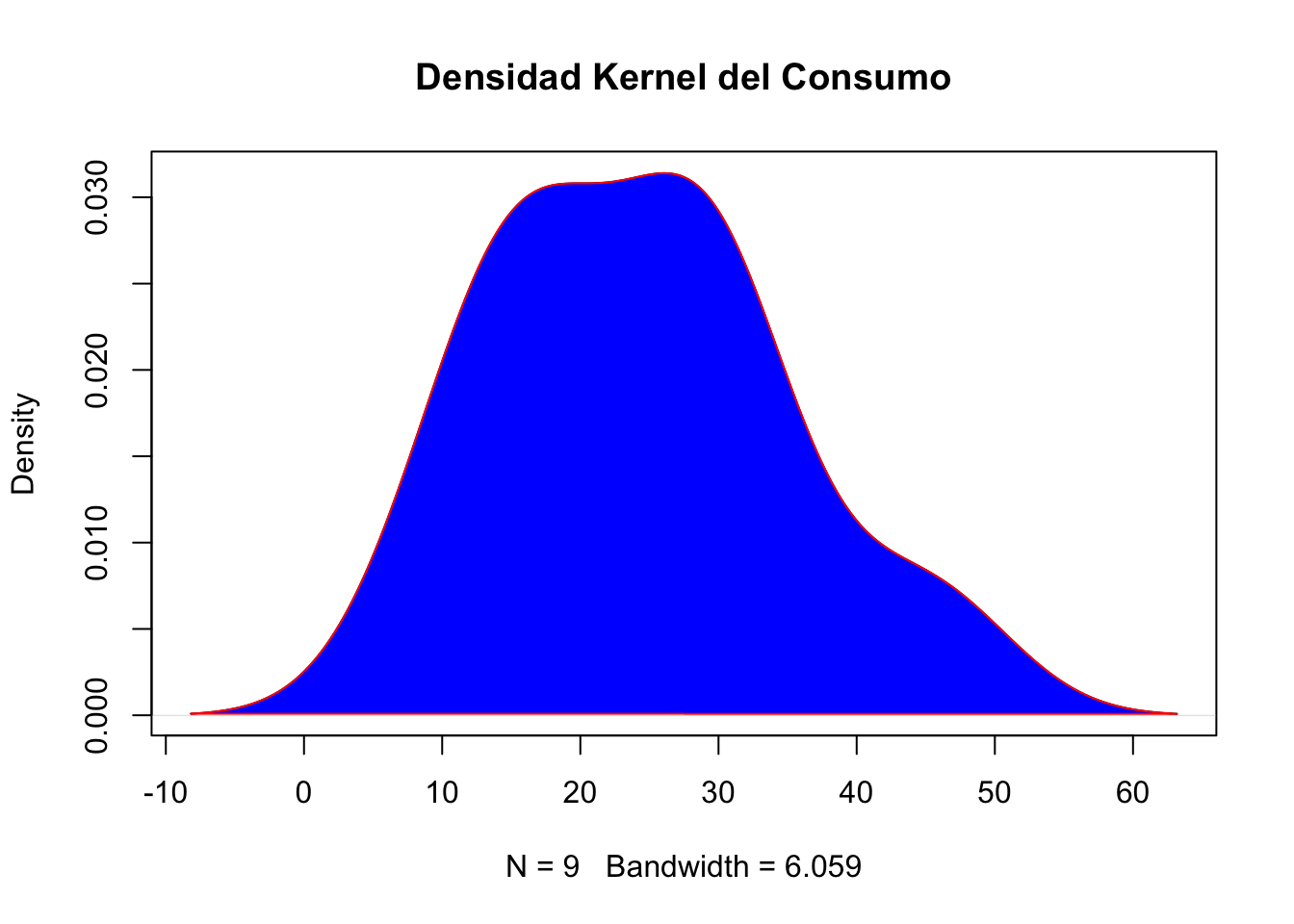
#Densidad con Histograma
x <- Pruebadatos$Consumo
h<-hist(x, breaks=5, col="blue", xlab="Consumo en unidades", ylab = "Frecuencia de consumo",
main="Histograma con curva de la dist. Normal")
xfit<-seq(min(x),max(x),length=40)
yfit<-dnorm(xfit,mean=mean(x),sd=sd(x))
yfit <- yfit*diff(h$mids[1:2])*length(x)
lines(xfit, yfit, col="red", lwd=2)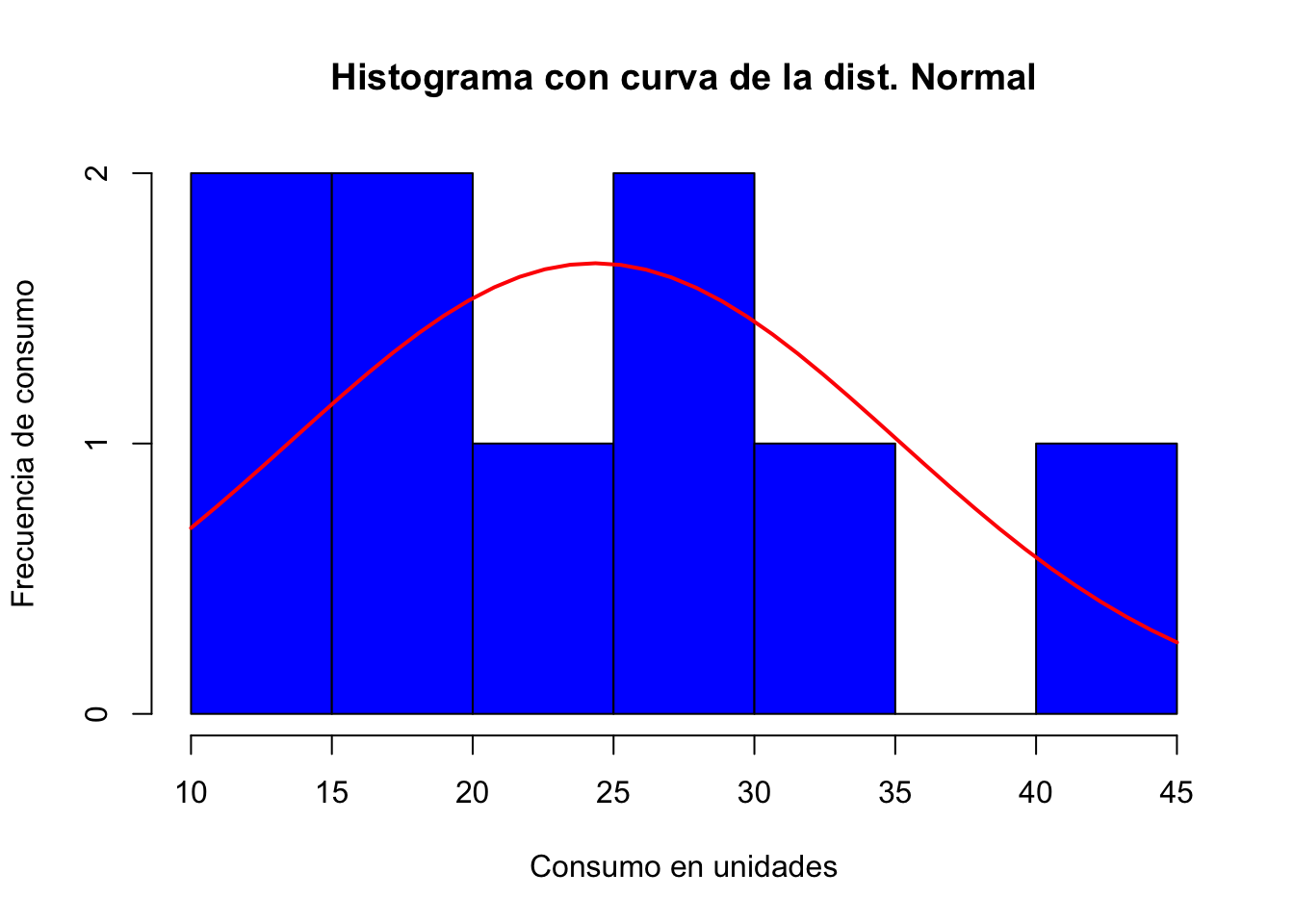
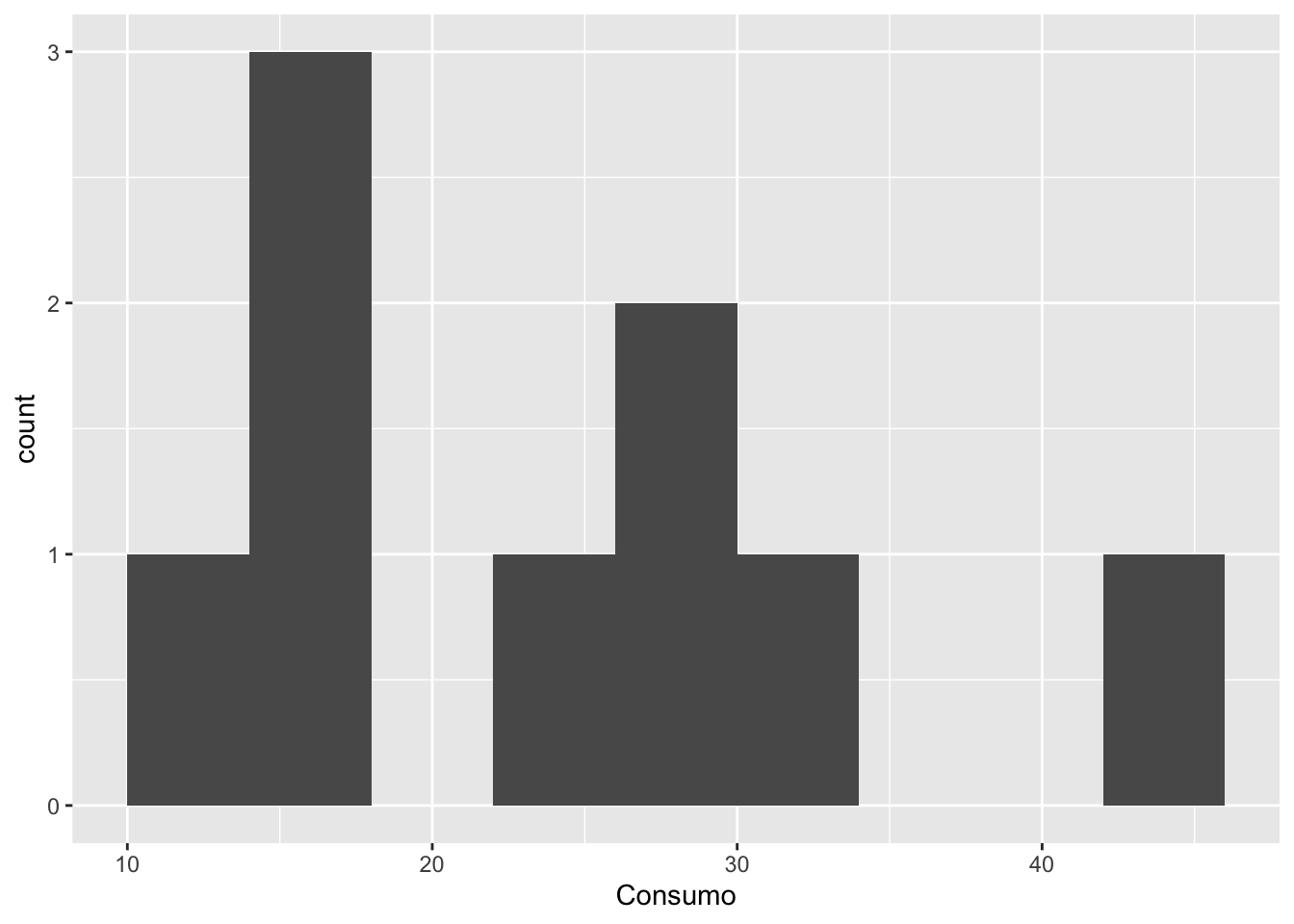
De lo anterior notamos que el consumo tiene una asimetría positiva (la cola de la distribución esta a la derecha) y tiene algunos datos en esa zona. Aunque hay una proporción de personas (40%) que contiene un consumo entre las 15 a 30 unidades respectivamente.
Con respecto a los gráficos
Recuerde que los gráficos que provee R como base son muy buenos, sin embargo puede usar otros paquetes como el de ggplot que tambien contiene otras mejoras visuales.
library(ggplot2)
ggplot(Pruebadatos, aes(x = Consumo)) +
geom_histogram()
# Con barras que decide el(la) autor(a) `binwidth`
ggplot(Pruebadatos, aes(x = Consumo)) +
geom_histogram(binwidth = 4)