Las variables dummy son fundamentales en econometría porque permiten incorporar información cualitativa en los modelos de regresión. Estas variables, que toman valores de 0 y 1, permiten analizar cómo características no numéricas, como el género, la educación o la región geográfica, afectan la variable dependiente. Al usarlas, es posible medir diferencias de comportamiento entre grupos y capturar efectos específicos que no podrían representarse con variables continuas, facilitando un análisis más completo y realista de los datos.
Resumen
En esta ocasión, se muestra en el lenguaje de R como se debe trabajar la Regresion múltiple con variables dicótomas o binarias tipo (Dummy). La guía intenta servir como insumo para trabajar variables de tipo cualitativo en modelos de regresión cuando estas son explicativas. Se plantean varios ejemplos: primero, con una sola variable dummy, luego con mas controles y así, hasta llegar al ejemplo con dummies de umbrales. Se adiciona también el estudio de comparativos con la prueba F o global de parámetros.
Modelo con variables explicativas categóricas
En algunos casos -o en muchos- de la vida real, nos cruzaremos con variables cuya característica es cualitativa, estas cualidades están al orden del día cuando medimos nivel de educación, si esta persona es bachiller, técnico, profesional, etc. También cuando se pregunta por uso de algún medio de transporte, es decir, si una persona elige ir en un taxi o bus a cierto lugar. Por otro lado, cuando se le pregunta si es de religión cristiana, musulmán, judia, etc. Todas estas referencias no medidas de forma tradicional como un número o continuas -con decimales-, hacen o dan uso de una transformación para poder utilizarlas.
Como son respuestas tipo de Si y No, una forma ficticia de hacerlo es mediante variables binarias o de tipo Dummy, para esto, tenga el ejemplo de una persona sea de raza color o (negra): \[D=\left\{\begin{matrix}
1 & \text{Si la persona es de raza afrodescendiente}\\
0 & \text{Si es de otra raza}
\end{matrix}\right.\]
Observe que aquella persona que en el cuestionario responda si o sea de ese color1 tomará inmediatamente el valor de 1 y de 0 si ocurre lo contrario2. Siguiendo con el análisis de salarios en base a los datos de Salarios, observe lo respondido en dicha encuesta.
# Cargamos los datoslibrary(readxl)Salarios <-read_excel("Salarios.xlsx")# Mirando los datostable(Salarios$black)
0 1
815 120
# Misma opción pero ahora con etiquetasSalarios$black<-factor(Salarios$black, labels =c("Otra raza", "Afro descendiente"))# Esto no hará perder la originalidad de los datostable(Salarios$black)
Otra raza Afro descendiente
815 120
De esto, conocemos entonces que 120 personas son o pertenecen a la raza “Afro” y 815 personas son de otras razas tales como (mestiza, india, blanca, etc). Piense por un momento que tan solo quiere mirar el promedio salarial de una persona Afro en comparación de otras “Razas”.
# Salida de modelo con huxregmd1<-lm(wage~black, data = Salarios)mresult <-huxreg("Tabla #1"= md1)# Mostrar tablamresult
Tabla #1
(Intercept)
990.648 ***
(13.853)
blackAfro descendiente
-254.806 ***
(38.669)
N
935
R2
0.044
logLik
-6917.099
AIC
13840.198
*** p < 0.001; ** p < 0.01; * p < 0.05.
Del resultado del modelo se encuentra que en efecto las personas Afrodescendientes en promedio ganan menos salario que cualquier persona de otra raza, esto significa, que si una persona se gana $990.67 -por no ser afro, una persona de color gana en promedio $735.842 dolares. El parámetro\(\beta_{i}\) de la dummy o variable binaria mide la diferencia entre los grupos que se están comparando. Para el caso de análisis esta incluso es significativa en su p-value en cada nivel de significancia estadística del 90%, 95% y 99% respectivamente.
La tabla #1 nos brinda los resultados del modelo: \(salario=\beta_{0}+\beta_{1}black+u_i\). Un modelo simple que mide la diferencia -si es que existe- entre salarios por grupos de raza o etnia. En muchas ocasiones el p-value del parámetro \(\beta_{i}\) no arrojará significancia, en ese caso, podríamos argumentar que no existe diferencia alguna entre grupos.
Estos resultados son concordantes con el del modelo anteriormente expuesto, observe que el \(\beta_{0}\) o constante es el mismo promedio del grupo de control o al que se le ha dado el valor de \(D_{i}=0\). Una gráfica de una variable dummy es:
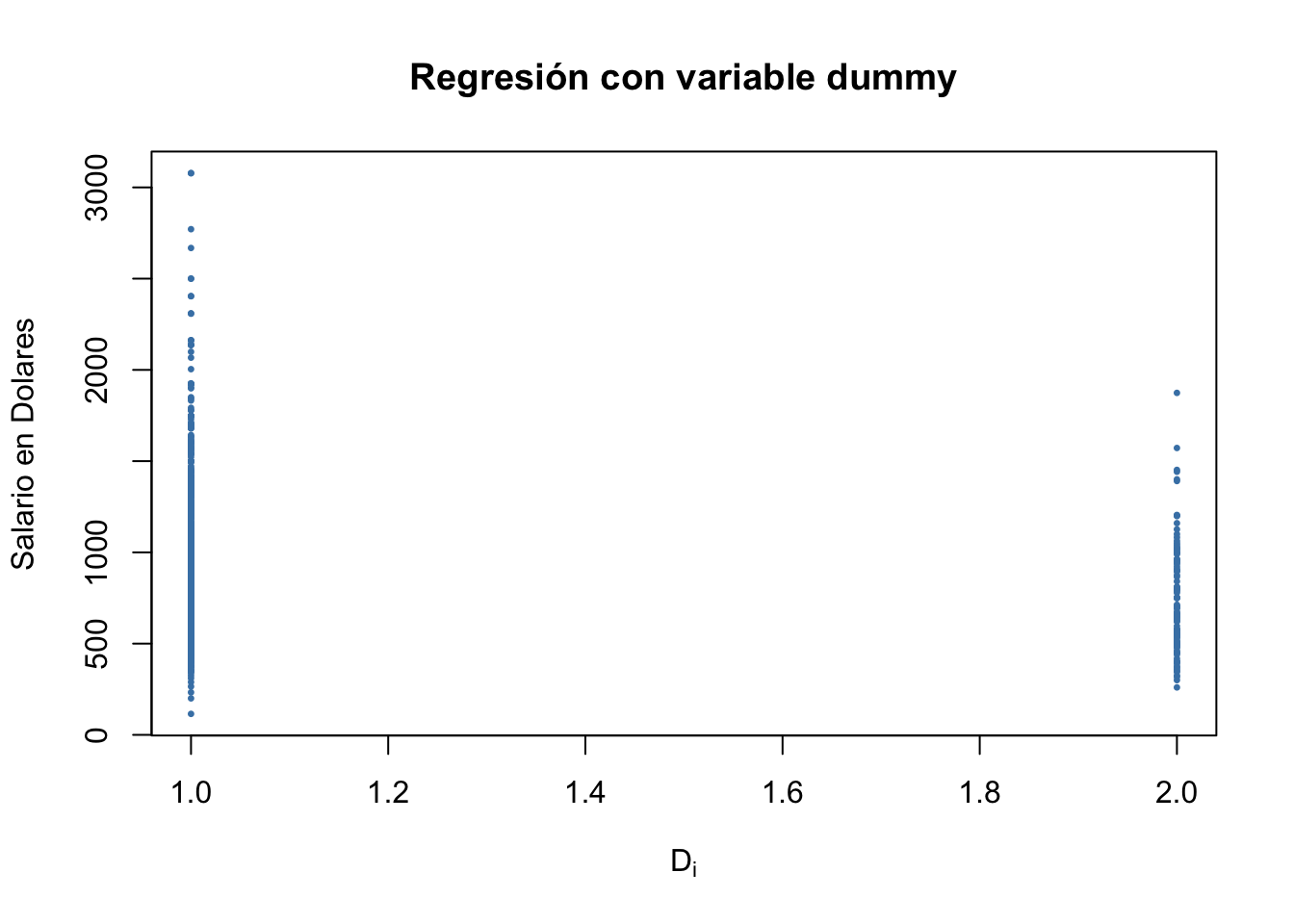
Salarios$black<-as.numeric(Salarios$black) # Formato numérico plot(Salarios$black,Salarios$wage, # Variable D primero luego dependientepch =20, # Opción de gráfico cex =0.5, # Tamaño de los puntoscol ="Steelblue", # Color xlab =expression(D[i]), # Para títulosylab ="Salario en Dolares",main ="Regresión con variable dummy")
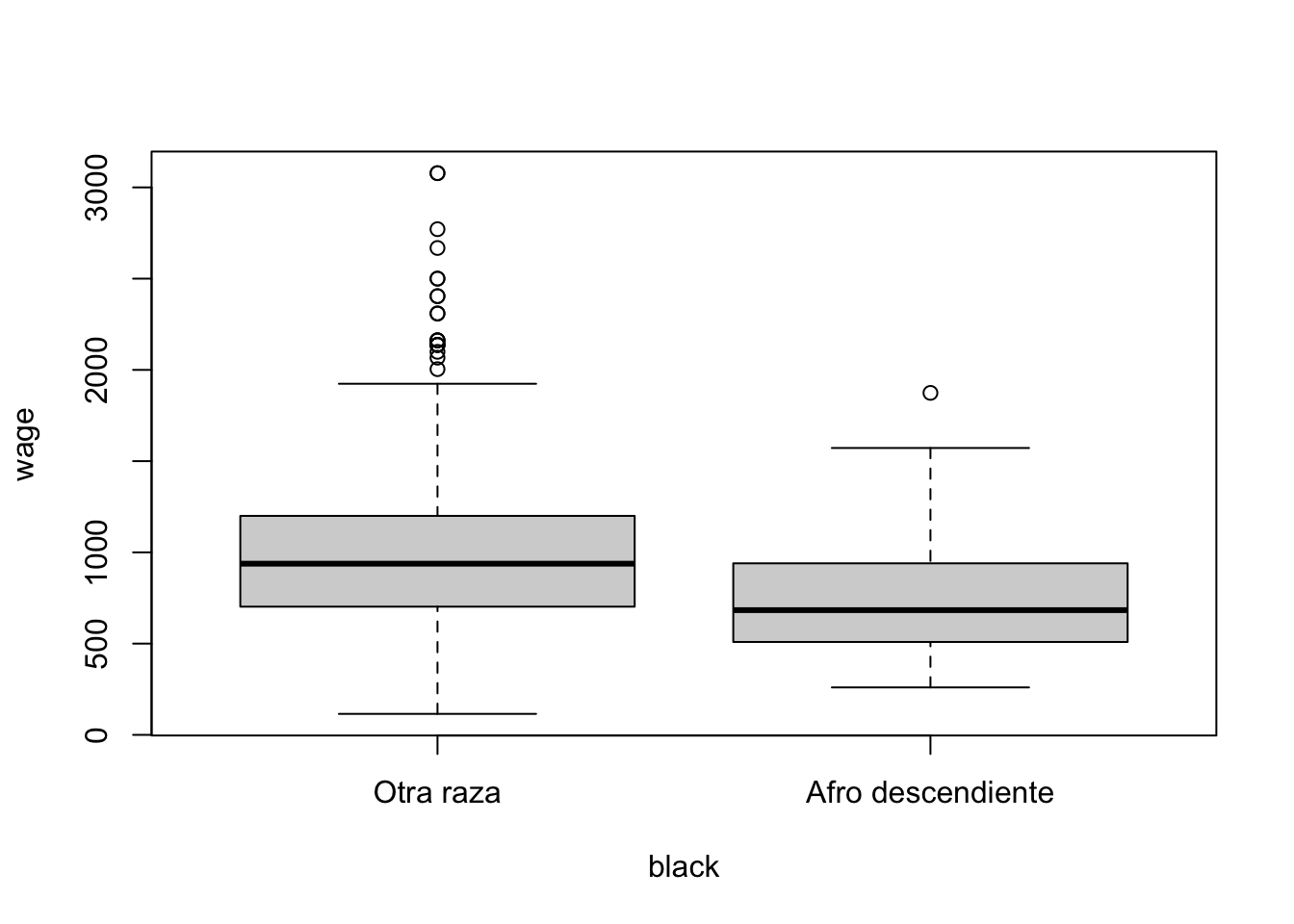
Los gráficos de variables Dummy no siempre son fáciles de interpretar, ya que comúnmente son dos lineas verticales que señalan una característica en comparación a otras variables cuantitativas. Como pasa a en la figura anterior. Una estrategia es usando mejor como factor y etiquetada la variable Dummy o usando el formato de factor y con eso ser mas explícitos en la explicación.
Usar la opción de factor y label dentro del código le da estructura al gráfico y el análisis se hace mas fácil. Es de notar que ambos grupos poseen ciertas diferencias entre si, ambas barras debieron ser similares. Si también se logra notar dentro del grupo en sí, existen diferencias salariales, lo que implica que hay en el grupo de “otra raza” personas que aún ganan mas (puntos que están por encima) de la caja. Mientras que dentro del grupo de los Afro los atípicos son pocos y tiende mas a tener un grupos de ellos con salarios aun mas bajo de los $ 736 dolares.
Como se menciono en el pie de pagina en el principio al iniciar la guía, en la base (Salarios) viene codificada la variable black con 1 y 2, siendo (1) “otras razas” y (2) los “Afros”. Esto en realidad no tiene implicación alguna, lo que importa es en realidad el orden como se establece dentro del modelo. De todas maneras para ser ordenados e ir en dirección de la teoría se pueden reemplazar así:
# Recodificando valores binarios 1 y 0 para categoríaSalarios$black<-as.numeric(Salarios$black) # No debe faltar esta opción de numéricosSalarios$black[Salarios$black ==1] <-0Salarios$black[Salarios$black ==2] <-1# Mirando los datos de nuevotable(Salarios$black)
0 1
815 120
Con otros controles cuantitativos
Si no se quiere trabajar con solo dummies sino también con otras variables \(x's\) pero de características cuantitativas y/o continuas, se puede estimar de esta manera: \[Y_{i}=\beta_{0} +\beta_{i} D_{i}+ \beta_{j} X_{j} + \mu\] Las interpretaciones no difieren, pero note que el parámetro de la constante\(\beta_0\) ya no solo involucrará el promedio de la otra categoría sino también la de los otros elementos que inciden sobre la variable dependiente que están en \(x_{i}\).
# Un modelo mas general con variable cualitativa y cuantitativamd2<-lm(wage~hours+black, data = Salarios)md2result<-huxreg("Tabla #2"= md2)md2result
Tabla #2
(Intercept)
1071.418 ***
(80.883)
hours
-1.826
(1.802)
black
-259.058 ***
(38.895)
N
935
R2
0.046
logLik
-6916.584
AIC
13841.168
*** p < 0.001; ** p < 0.01; * p < 0.05.
Al incluir variables explicativas sobre la regresión es notable que cambie la constante, pero que se mantenga -o que se modifique- el parámetro de la variable cualitativa es normal, ya que estamos en una regresión donde la dependiente es afectada ahora por mas variables explicativas. El modelo 1 incorpora solo la variable cualitativa como explicativa y el modelo 2 posee dos variables, la interpretación no varia, las personas ``Afro’’ ganan en promedio menos salario que las demás razas manteniendo constante las horas de trabajo.
También es factible muchas veces que la variable cualitativa tenga cierto número de respuestas, como Estrato 1, Estrato 2, Estrato 3, etc., como también variables que involucran mas de una cualidad como por ejemplo: alto, bajo, mediano.} Además pueden ser variables diferenciadas por ocupación o por aquella variable que el investigador considere como importante. En R como en otros softwares, es importante decirles que se trabaja en formato de factor y es bueno hacerlo con etiquetas o labels, de lo contrario no mostrará el verdadero valor del parámetro que se asocia a esa variable.
# Regresión por categorías # Inventemos una variable ahoraset.seed(1239) # Código de replicaocupacion<-sample(1:5,935,replace=T) # Variable de ocupación Salarios$ocupacion<-ocupacionSalarios$ocupacion<-factor(Salarios$ocupacion, labels =c("Técnico", "Profesional", "Ejecutivo","Auxiliar", "Pasante")) table(Salarios$ocupacion)
md3<-lm(wage~hours+black+ocupacion, data = Salarios)md3result<-huxreg("Tabla #3"= md3)md3result
Tabla #3
(Intercept)
1041.144 ***
(86.879)
hours
-1.838
(1.806)
black
-260.256 ***
(38.869)
ocupacionProfesional
52.717
(41.976)
ocupacionEjecutivo
74.336
(41.755)
ocupacionAuxiliar
-9.167
(40.757)
ocupacionPasante
40.925
(40.389)
N
935
R2
0.052
logLik
-6913.593
AIC
13843.185
*** p < 0.001; ** p < 0.01; * p < 0.05.
El modelo 3 de la tabla anterior muestra la diferencia salarial por ocupación, siendo aquellos que pertenecen al grado Ejecutivo ganan mas en promedio $ 74.34 dolares que las demás ocupaciones cuando la base es Técnico. Observe que el sistema de R ha omitido automáticamente una de las categorías (Técnico), para evitar el problema de la trampa de la dummy o multicolinealidad perfecta3 entre variables. Manualmente este hecho también puede ser tratado por el investigador y cambiar la omisión de esa variable y mostrar otra como base. Un ejemplo de código puede ser:
#Regresión por categorías cambiando baseSalarios$ocupacion<-relevel(Salarios$ocupacion, "Profesional")md4<-lm(wage~hours+black+ocupacion, data = Salarios)md4result<-huxreg("Tabla #4"= md4)md4result
Tabla #4
(Intercept)
1093.861 ***
(85.558)
hours
-1.838
(1.806)
black
-260.256 ***
(38.869)
ocupacionTécnico
-52.717
(41.976)
ocupacionEjecutivo
21.619
(42.124)
ocupacionAuxiliar
-61.884
(41.083)
ocupacionPasante
-11.792
(40.771)
N
935
R2
0.052
logLik
-6913.593
AIC
13843.185
*** p < 0.001; ** p < 0.01; * p < 0.05.
La siguiente forma solo brindará el promedio de salario que se gana cada ocupación como tal, -incluye a todas las categorías-, lo resultados son muy similares a los obtenidos anteriormente, solo que acá se hace sin comparación base. Recuerde siempre que todo modelo debe tener el término de la constante -así que-, es preferido siempre estimar de esta manera, con su respectiva constante o \(\beta_{0}\).
md5<-lm(wage~0+hours+black+ocupacion, data = Salarios)md5result<-huxreg("Tabla #5"= md5)md5result
Tabla #5
hours
-1.838
(1.806)
black
-260.256 ***
(38.869)
ocupacionProfesional
1093.861 ***
(85.558)
ocupacionTécnico
1041.144 ***
(86.879)
ocupacionEjecutivo
1115.479 ***
(85.269)
ocupacionAuxiliar
1031.977 ***
(83.430)
ocupacionPasante
1082.069 ***
(84.444)
N
935
R2
0.857
logLik
-6913.593
AIC
13843.185
*** p < 0.001; ** p < 0.01; * p < 0.05.
Interacciones entre variables cualitativas
De las variables cualitativas se pueden hacer análisis adicionales, implica analizar por grupos, estas interacciones se pueden hacer entre variables cuantitativas y cualitativas, e incluso aún mejor, con variables cualitativa- cualitativa. Un ejemplo es mirar el promedio del salario de una persona “Afro” y que además vive en el sur.
\[D_{1}=\left\{\begin{matrix}
1 & \text{Si la persona es de raza afrodescendiente}\\
0 & \text{Si es de otra raza}
\end{matrix}\right.
\quad
D_{2}=\left\{\begin{matrix}
1 & \text{Si la persona vive en el sur}\\
0 & \text{Si vive en otra zona geográfica}
\end{matrix}\right.\]
La idea es tener una multiplicación lo que es una interacción entre términos que es \(D_{1}\times D_{2}\), lo que brindará una especie de doble calificación y una diferencia de ese grupo.
Raza
Sur
Resultado
Otra raza
Si
0
Afro-descendientes
No
0
Otra raza
No
0
Afro-descendientes
Si
1
Esto nos permitirá mirar cuanto gana una persona que es “Afro” y vive en el “Sur” y que por esas dos condiciones se profundice la brecha salarial para el caso u ocurra algo contrario.
md6<-lm(wage~hours+black+south+black:south, data = Salarios)md6result<-huxreg("Tabla #6"= md6)md6result
Tabla #6
(Intercept)
1097.216 ***
(80.880)
hours
-1.849
(1.790)
black
-159.485 **
(61.599)
south
-83.094 **
(30.080)
black:south
-113.331
(80.265)
N
935
R2
0.060
logLik
-6909.303
AIC
13830.605
*** p < 0.001; ** p < 0.01; * p < 0.05.
Al parecer dentro del grupo de “Afros” vivir en el sur no existe diferencia salarial en comparación a otros “Afros” que viven en otro lugar. Si el efecto hubiere sido significativo, se podría establecer que el evento de ser “Afro” y “Vivir en el sur” con respecto a los demás “Afros” tuviera una mayor implicación o incidencia y estuviera en condición de una mayor vulnerabilidad.
Variable Dummy con variable Continua
Muchas veces podemos hacer combinación entre una variable por grupo. Miremos lo siguiente:
md61<-lm(wage~hours+black+black:hours, data = Salarios)md61result<-huxreg("Tabla #6.1"= md61)md61result
Tabla #6.1
(Intercept)
1066.406 ***
(85.511)
hours
-1.713
(1.908)
black
-214.498
(248.667)
hours:black
-1.057
(5.827)
N
935
R2
0.046
logLik
-6916.567
AIC
13843.135
*** p < 0.001; ** p < 0.01; * p < 0.05.
El término de la interacción hours:black muestra solo el efecto parcial de ser Afro con el conjunto de horas que trabaja la persona. es decir, si queremos mirar solo el grupo de afros por nivel de horas, su efecto diferencial con respecto a los demás grupos de raza o género seria diferente en 1 dolar. Lo que quiere decir que tienden a pagarles menos de 1 dolar si esta fuera significativa, cuando solo se evalua por grupo. Para esta regresión no hay una diferencia significativa entre grupos de razas.
Mire ahora lo siguiente:
# Modelo solo de afrodescendientes con horaslm(wage~hours, data=Salarios, subset=(black==1))
Sin la interacción tendríamos que filtrar o hacer uso de siempre de la función de subconjuntos entre los datos, lo mismo de decir subset dentro de la opción de las personas que cumplen con cierta condición. Para el ejemplo notamos los parámetros que tiene una persona afro versus una de otra raza/genero.
Observe ademas que si extraemos los coeficientes de esas regresiones qu realizamos tendríamos:
\[-2.77-(-1.713)=-1.057\] Que es el efecto diferencial que hemos obtenido cuando hicimos la regresión original entre la interacción de la cuantitativa con la cualitativa.
Desde luego depende también del investigador el establecimiento o formato de resultados que quiere dar a conocer en su trabajo investigativo.
Variable Continua con variable Continua
Este proceso no es tan frecuente usarlo dentro de las regresiones para mirar efectos de grupos pero si para ver especificaciones de los modelos. La interacción en este caso es mas visual e incluso geométrico por lo de la linea de ajuste del modelo con el mapa de dispersión de variables. Sin embargo miremos solo la empleabilidad o una de las formas de hacerlo en R.
md62<-lm(wage~hours+exper+exper:hours, data = Salarios)md62result<-huxreg("Tabla #6.2"= md62)md62result
Tabla #6.2
(Intercept)
1173.818 ***
(231.960)
hours
-4.913
(5.152)
exper
-17.215
(19.294)
hours:exper
0.393
(0.432)
N
935
R2
0.001
logLik
-6937.905
AIC
13885.809
*** p < 0.001; ** p < 0.01; * p < 0.05.
Note que para este caso el parámetro de 0.33 no dice nada, aparte que no es significativo. Si quizas fuera significativo habría que mirar el grado de ajuste de la regresión. Recuerde que cuando tenemos ese tipo de variable o producto es casi similar cuando tendríamos una variable como por ejemplo \(x^2\) en el modelo de regresión, anteriormente ya se habia hablado de eso dentro del formato de la regresión.
Dummy Umbral
En algunas ocasiones también se pueden crear variables cualitativas a partir de un umbral (variable índice) o que se pueda ordenar de menor a mayor. Tomaremos un ejemplo con la variable de educación. Se establecerá como nivel básico aquellos que tengan una educación menor a 12 años y aquellos mayores a este nivel serán considerados como nivel Intermedio. Con esto se agrupa por grupos en una variable que es considerada continua a una simplemente cualitativa. Recuerde que el bachillerato completo solo se logra con 11 años aprobados, 5 de primaria y 6 de secundaria respectivamente.
#Regresión con umbral o variable continua:#Se toma una variable cuantitativa o índiceSalarios$umbral <-ifelse(Salarios$educ <12 ,1,0)#Modelomd7<-lm(wage~tenure+exper+black+umbral, data = Salarios)md7result<-huxreg("Tabla #7"= md7)md7result
Tabla #7
(Intercept)
921.935 ***
(37.983)
tenure
8.400 **
(2.616)
exper
1.819
(3.132)
black
-228.215 ***
(38.590)
umbral
-175.395 ***
(45.674)
N
935
R2
0.072
logLik
-6903.451
AIC
13818.902
*** p < 0.001; ** p < 0.01; * p < 0.05.
Las personas con un nivel básico ganan en promedio menos salario $175.4 que el nivel intermedio. La educación superior genera mejores retornos en salarios que la educación básica para las observaciones de este modelo. Se pueden establecer interacciones entre variables, pero eso siempre dependerá de lo que quiere responder cada investigador.
Modelo con variable Dummy ranking
En otras ocasiones se cuentan con variables que contienen información de tipo (“Examen”) o van en una relación de 0-100 o los valores específicos que han establecido los recopiladores de información. De tener esto y contar con grupos que han sacado específicamente un rango de valores, se pueden agrupar dentro de una variable dummy, que contendrá o dará el valor de 1 si las personas pertenecen a dicho grupo y de 0 si ocurre lo contrario.
\[\begin{aligned}
D_{1}=\left\{\begin{matrix}
1 & \text{Si la persona sacó entre 0-5 en la prueba}\\
0 & \text{De lo contrario}
\end{matrix}\right.
&
\quad
D_{2}=\left\{\begin{matrix}
1 & \text{Si la persona sacó entre 6-10 en la prueba}\\
0 & \text{De lo contrario}
\end{matrix}\right.
\\
D_{3}=\left\{\begin{matrix}
1 & \text{Si la persona sacó entre 11-15 en la prueba}\\
0 & \text{De lo contrario}
\end{matrix}\right.
&
\quad
D_{4}=\left\{\begin{matrix}
1 & \text{Si la persona sacó entre 16-20 en la prueba}\\
0 & \text{De lo contrario}
\end{matrix}\right.
\end{aligned}\]
De esta forma y de acuerdo al número de cortes o grupos que establezca el investigador, tendrá grupos de comparación. Evitando la trampa de las dummies, se omite una variable que inmediatamente se irá al \(\beta_{0}\) o constante y será el grupo de referencia para realizar las comparaciones respectivas.
#Índices completos#Modelo con variable de notas o prueba de conocimientostable(Salarios$KWW)
#Definen puntos de cortecorte<-c(20,25,30,35,40,45,50,60)#se crea la variable rankiadaSalarios$ranking<-cut(Salarios$KWW, corte)#Una tablatable(Salarios$ranking)
Con esto ya usted sabe o podrá usar las observaciones por ranking de datos y puntos de corte que automáticamente el algoritmo ya ha hecho para mostrar. A continuación la estimación en un modelo especifico
#Modelo rankeadomd8<-lm(wage~exper+black+ranking, data = Salarios)md8result<-huxreg("Tabla #8"= md8)md8result
Tabla #8
(Intercept)
845.407 ***
(55.631)
exper
0.444
(2.895)
black
-182.933 ***
(40.110)
ranking(25,30]
21.305
(55.385)
ranking(30,35]
22.709
(52.607)
ranking(35,40]
138.102 **
(50.690)
ranking(40,45]
254.785 ***
(53.542)
ranking(45,50]
381.919 ***
(63.114)
ranking(50,60]
619.472 ***
(128.224)
N
906
R2
0.139
logLik
-6658.624
AIC
13337.248
*** p < 0.001; ** p < 0.01; * p < 0.05.
#Si quiere cambiar de referencia o base (**Opcional**)Salarios$ranking<-relevel(Salarios$ranking, "(50,60]")
Una forma de interpretar esto, es tomar una referencia de la variable de Ranking y leer teniendo en cuenta como referencia el primer grupo. Para este caso, aquellos que cuya prueba han sacado un rango entre 50 y 60 puntos ganan en promedio $ 619.46 de salario mas que el grupo que solo sacó en la prueba entre 20 y 25 puntos (grupo base).
Prueba F para diferencia entre grupos
La prueba F es un test grueso ya que permite realizar conjuntamente evaluación estadística entre parámetros del modelo. A diferencia de la t-student este test usa todas las variables implicadas en la regresión: \[F= \frac{(SSR_{r}-SSR_{nr}/k)}{SSR_{nr}/(n-2k)} \equiv \frac{R^{2}_{nr}-R^{2}_{r}}{(1-R^{2}_{nr})}\cdot \frac{n-k-1}{q}\] La prueba va en el orden de: \[\begin{aligned}
H_{0}&: \beta_{i}=\beta_{j}=0 \quad con\; i\neq j \\
H_{1}&: \beta_{i}\neq \beta_{j}\neq 0
\end{aligned}\]
La consideración será tener a \(F_{calculado}>F_{critico}\) para rechazar la hipótesis nula \(H_{0}\), que ningún parámetro es significativo para el modelo. Partamos de un caso que quiere medir que tanta implicación o relevancia (tienen) las variables educ y age dentro de un modelo que ha sido establecido como \(salario=f(educ,hours,age)\). Las condiciones varian también dependiendo del investigador, puede escoger sacar o quitar una sola variable o quitar hours, como se desee.
# Prueba F# Regresión no restringidamodf.nr <-lm(wage ~ hours+educ+age, data=Salarios)# Restricción educ y age (las sacamos o eliminamos del modelo)modf.r <-lm(wage ~ hours, data=Salarios)# R2:( r2.nr <-summary(modf.nr)$r.squared )
[1] 0.1347359
( r2.r <-summary(modf.r)$r.squared )
[1] 9.033176e-05
# F estadistico: 935-3-1 y q=2 restriciones935-3-1
[1] 931
( F <- (r2.nr-r2.r) / (1-r2.nr) *931/2 )
[1] 72.43746
# p value = 1-cdf de la distribución F:1-pf(F, 2,931)
[1] 0
#De forma directa con el paquete CARlibrary(car)# Forma manual:SSE.nr=sum(modf.nr$residuals**2)SSE.r=sum(modf.r$residuals**2)miH0<-c("educ","age")linearHypothesis(modf.nr,miH0)
Res.Df
RSS
Df
Sum of Sq
F
Pr(>F)
933
1.53e+08
931
1.32e+08
2
2.06e+07
72.4
5.77e-30
# Tabla ANOVA:Anova(modf.nr)
Sum Sq
Df
F value
Pr(>F)
2.91e+05
1
2.05
0.153
1.68e+07
1
118
4.94e-26
4e+06
1
28.2
1.39e-07
1.32e+08
931
Para esta parte se encuentra y se tiene suficiente evidencia -el \(F_{cal}>F_{crit}\)- estadística de que las variables educ y age deben estar en el modelo y por ende son relevantes.
Comparando entre grupos
La prueba F también sirve para hacer comparaciones entre grupos. Suponga que el objetivo de una investigación es comparar el salario de una persona que pertenece al grupo de “Afrodescendientes” con todas las “otras razas” pero teniendo en cuenta todas y cada una de las variables asociadas a la educación, experiencia y fidelidad con el actual empleador. Para esto, se requiere realizar una prueba F.
# Modelo comparando dos grupos # Modelo originalmodr<-lm(wage~educ+exper+tenure, data = Salarios)summary(modr)
Call:
lm(formula = wage ~ educ + exper + tenure, data = Salarios)
Residuals:
Min 1Q Median 3Q Max
-866.29 -249.23 -51.07 189.62 2190.01
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -276.240 106.702 -2.589 0.009778 **
educ 74.415 6.287 11.836 < 2e-16 ***
exper 14.892 3.253 4.578 5.33e-06 ***
tenure 8.257 2.498 3.306 0.000983 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 374.3 on 931 degrees of freedom
Multiple R-squared: 0.1459, Adjusted R-squared: 0.1431
F-statistic: 53 on 3 and 931 DF, p-value: < 2.2e-16
modo<-lm(wage~black*(educ+exper+tenure), data = Salarios) summary(modo)
Call:
lm(formula = wage ~ black * (educ + exper + tenure), data = Salarios)
Residuals:
Min 1Q Median 3Q Max
-895.5 -241.7 -46.8 184.5 2159.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -220.842 112.811 -1.958 0.0506 .
black 331.709 357.360 0.928 0.3535
educ 72.738 6.571 11.069 < 2e-16 ***
exper 15.470 3.482 4.443 9.96e-06 ***
tenure 5.874 2.629 2.235 0.0257 *
black:educ -40.646 23.175 -1.754 0.0798 .
black:exper -6.423 9.120 -0.704 0.4815
black:tenure 12.726 7.836 1.624 0.1047
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 369.5 on 927 degrees of freedom
Multiple R-squared: 0.1712, Adjusted R-squared: 0.1649
F-statistic: 27.35 on 7 and 927 DF, p-value: < 2.2e-16
# Prueba entre grupos con la FlinearHypothesis(modo, matchCoefs(modo, "black"))
Res.Df
RSS
Df
Sum of Sq
F
Pr(>F)
931
1.3e+08
927
1.27e+08
4
3.86e+06
7.07
1.32e-05
Debe mirar que en este caso, si existen diferencias considerables con respecto a los “Afros” y los demás grupos de referencia, sobre todo en lo que tiene que ver con la educación, ya que las diferencias son mucho mas marcadas. La prueba F en este caso permite rechazar a un nivel de significancia del 99% la no relevancia y/o importancia de estas variables dentro del modelo.
Bibliografía
Wooldridge, J. M. (2015). Introductory econometrics: A modern approach. Cengage learning.
Footnotes
La base de datos es de un ejemplo del libro de Wooldridge y toma como referencia Black como raza afro descendiente, en ningún momento se hace incorrecta alusión a un irrespeto racial o despectivo al traducir literalmente ``Negro’’.↩︎
En la base esta categoría viene con datos de 1 para otras razas y de 2 para los Black, pero el tratamiento es el mismo en el modelo como si se tratara de cero y unos.↩︎